
Connexion de l'API Google à Databricks
Ce document explique comment configurer les informations d'identification pour se connecter à n'importe quelle API Google telle que Google Earth Engine, BigTable et BigQuery.
Hypothèses
- La DHSF ne fournira pas d'identifiants pour la Google Cloud Platform et suppose que l'utilisateur a reçu un accès de son département.
- L'utilisateur connaît le produit Google utilisé
1. Créer un projet Google Cloud
Suivez le lien pour savoir comment créer un projet Google Cloud.
2. Activer les API et les services nécessaires
Une fois votre projet créé et sélectionné, dans la barre de navigation, cliquez sur "APIs & Services" :
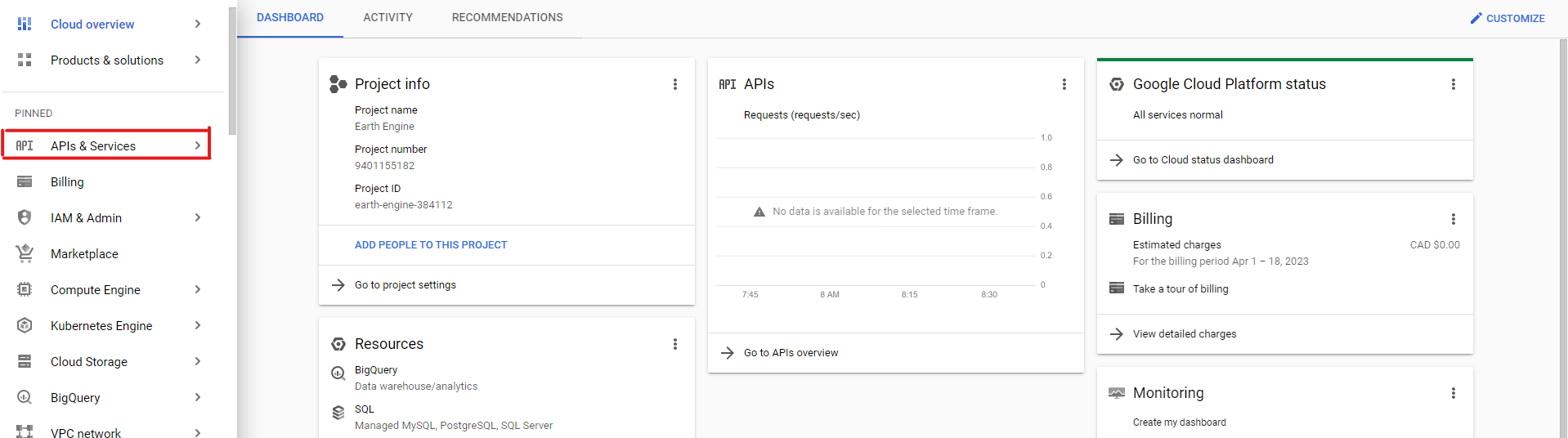
Cliquez ensuite sur "Enable APIs & Services" :
 Recherchez les services dont vous pourriez avoir besoin, tels que "BigQuery API", "BigTable API", "Earth Engine API", etc. Il devrait alors apparaître dans les résultats de la recherche. Cliquez dessus, puis cliquez sur "Enable".
Recherchez les services dont vous pourriez avoir besoin, tels que "BigQuery API", "BigTable API", "Earth Engine API", etc. Il devrait alors apparaître dans les résultats de la recherche. Cliquez dessus, puis cliquez sur "Enable".
3. Créez un compte de service et obtenez une clé privée.
Une fois que vous avez activé les API dont vous avez besoin dans votre projet, ouvrez le menu de navigation et cliquez sur "IAM & Admin" :
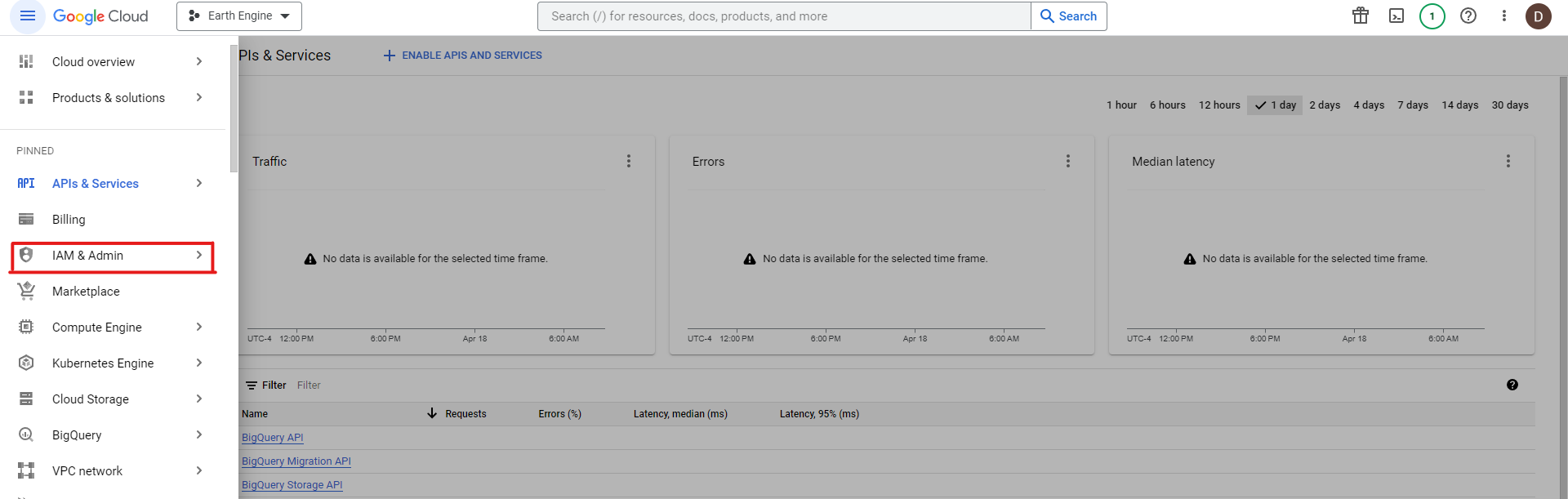
Cliquez ensuite sur "Comptes de service" :
 Créez ensuite un nouveau compte de service :
Créez ensuite un nouveau compte de service :

Saisissez les informations nécessaires (nom, ID, description) dans la première étape, puis dans la deuxième étape, sélectionnez les rôles nécessaires pour votre compte de service. En fonction du service que vous utilisez, vous devrez sélectionner les rôles appropriés : par exemple, si vous utilisez l'API Earth Engine, vous devez sélectionner les rôles admin, viewer ou writer, en fonction de vos besoins :
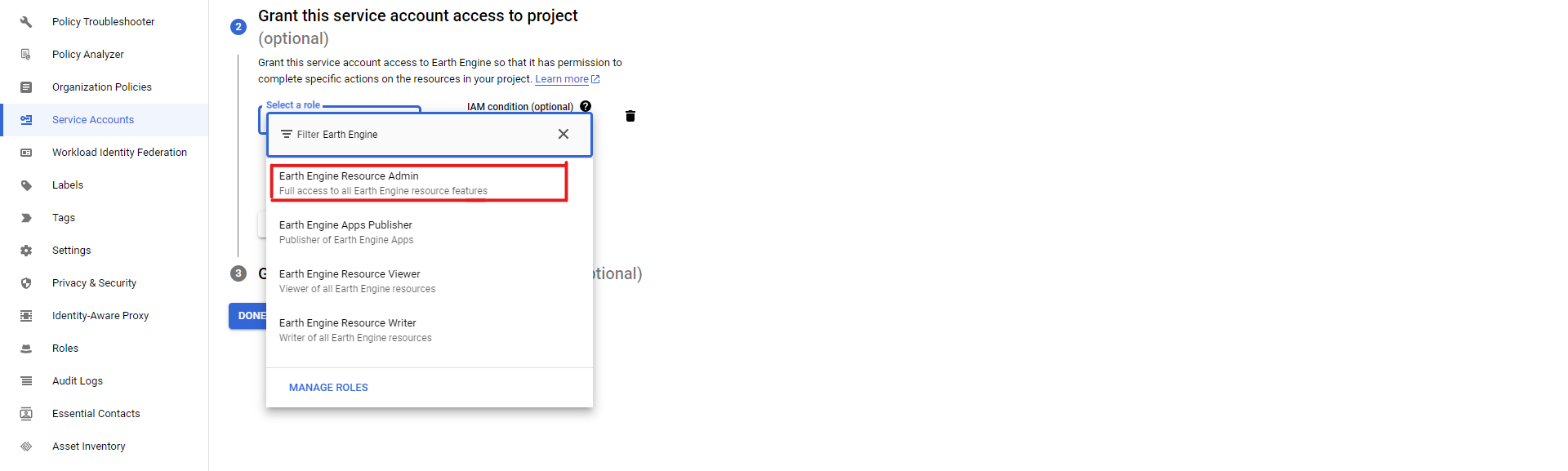 Ensuite, sautez la troisième étape et créez votre compte de service en cliquant sur "Terminé". Cela devrait vous ramener à la liste de tous les comptes de service et vous devriez voir le compte de service que vous venez de créer listé. Cliquez dessus, puis cliquez sur l'onglet "Clés" :
Ensuite, sautez la troisième étape et créez votre compte de service en cliquant sur "Terminé". Cela devrait vous ramener à la liste de tous les comptes de service et vous devriez voir le compte de service que vous venez de créer listé. Cliquez dessus, puis cliquez sur l'onglet "Clés" :

Cliquez sur "Add Key" et "Create new key", et sélectionnez le format JSON pour votre clé :
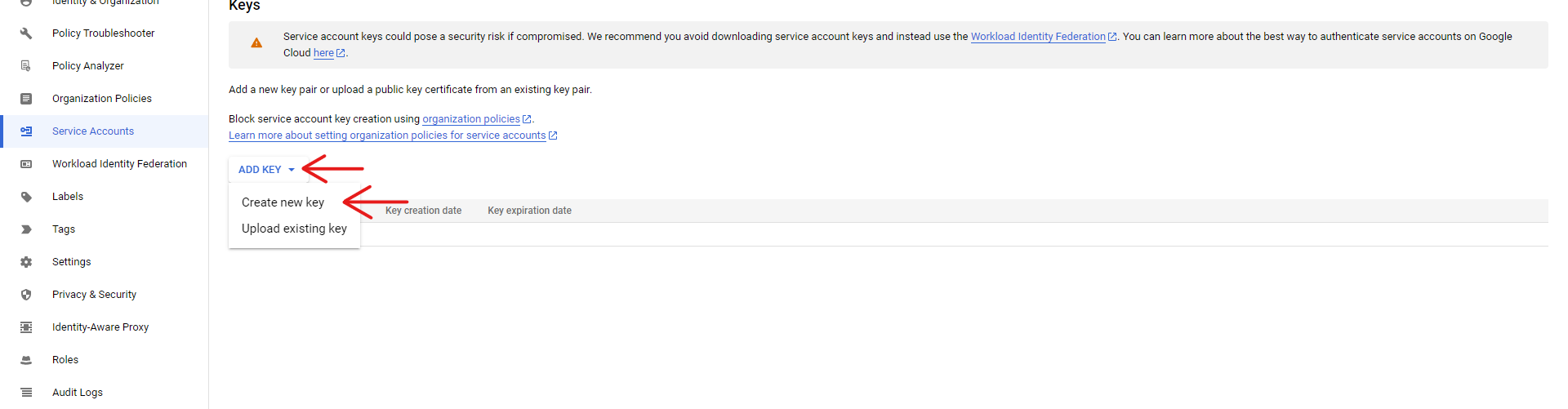 Cela créera automatiquement une clé et la téléchargera. Veillez à conserver cette clé.
Cela créera automatiquement une clé et la téléchargera. Veillez à conserver cette clé.
4. Enregistrez votre projet cloud
Dans le cas de certaines API, il se peut que vous deviez enregistrer votre projet Google Cloud. Par exemple, Google Earth Engine nous demande de naviguer vers [ce lien d'enregistrement] (https://code.earthengine.google.com/register) et de nous connecter à l'aide du même compte Google que celui que vous utilisez pour Google Cloud, afin d'enregistrer votre projet.
Pour enregistrer votre Google Cloud
Sélectionnez "Utiliser avec un projet cloud"
Sélectionnez "Utilisation payante" ou "Utilisation non payante" en fonction de vos besoins personnels et de votre rôle. Dans notre cas, nous sélectionnerons "Usage non rémunéré". Le système vous invite à sélectionner un type de projet, choisissez "Gouvernement".
Sélectionnez "Choose an existing cloud project" et sélectionnez le projet dans lequel vous avez activé l'API Google Earth Engine.
Enfin, vérifiez les informations que vous avez fournies et confirmez-les.
5. Installer le SDK côté client pour votre service
Votre service peut nécessiter l'installation d'un paquetage sur Databricks afin de l'utiliser, comme c'est le cas pour l'API Google Earth Engine. Pour cette étape, nous allons démontrer l'installation de l'API Earth Engine de Google, mais tous les paquets peuvent être installés de cette manière.
Il y a deux façons d'installer un paquetage. Pour installer un paquetage Python dans la portée du notebook, exécutez la ligne magique Python suivante (assurez-vous de remplacer earthengine-api par le nom de votre paquetage, que vous devrez peut-être rechercher en ligne) :
%pip install earthengine-api
Si vous réussissez à exécuter cette ligne, passez à l'étape suivante. Si vous souhaitez plutôt installer le package sur le cluster, ouvrez la barre de navigation sur Databricks, et cliquez sur "Compute". Sélectionnez le cluster sur lequel vous souhaitez installer le paquet, puis cliquez sur "libraries" :
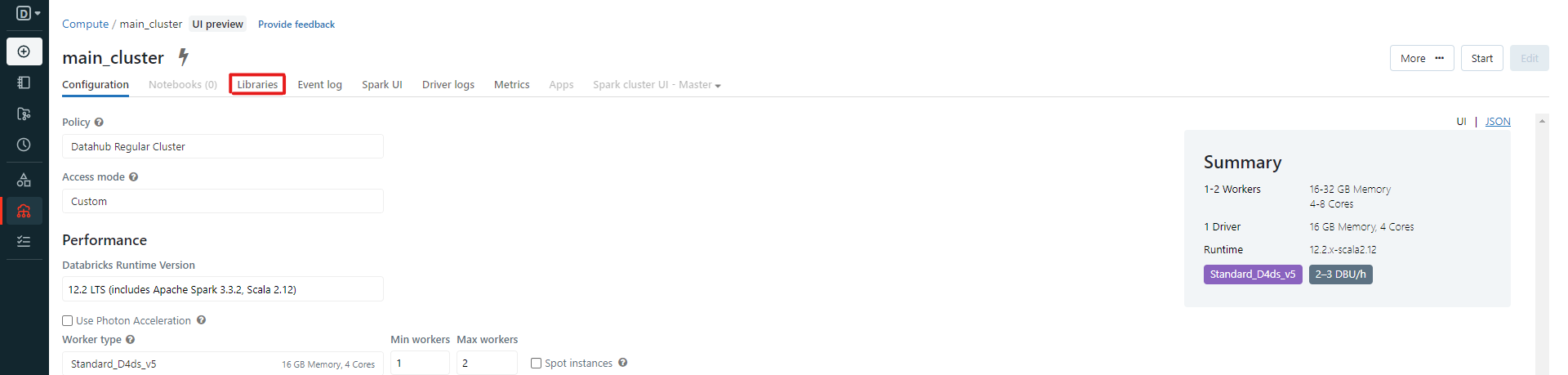
Cliquez ensuite sur "Installer nouveau" :
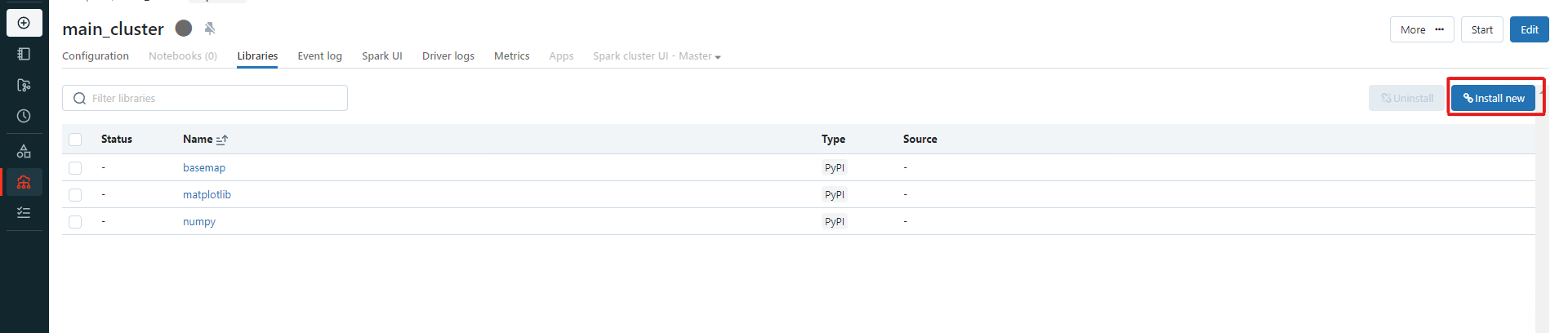 Dans le menu contextuel, sélectionnez PyPI, et dans le champ "package name", entrez le nom de votre paquet (pour nous :
Dans le menu contextuel, sélectionnez PyPI, et dans le champ "package name", entrez le nom de votre paquet (pour nous : earthengine-api), puis cliquez sur "Install". Une fois que vous aurez démarré votre cluster, il installera la bibliothèque et elle sera disponible sur tous les notebooks qui sont attachés à ce cluster.
6. Utilisation de votre API Google
Commencez par télécharger la clé privée que nous avons créée à l'étape 3. Vous pouvez le faire soit en téléchargeant vers votre stockage DHSF, soit en téléchargeant directement vers Databricks. Prenez note de l'endroit où votre clé est stockée, puis utilisez le code suivant pour y accéder. Ce code a été créé pour l'utilisation de l'API Earth Engine, mais le processus est très similaire d'un service à l'autre.
Utilisation d'une clé privée téléchargée via Databricks File Upload
importation ee
# Entrez l'email associé à votre compte de service créé à l'étape 3 :
compte_service = 'my-service-account@...gserviceaccount.com'
# Dans notre cas :
compte_service = 'david-rene@earth-engine-384112.iam.gserviceaccount.com'
# Entrez le chemin d'accès à vos informations d'identification :
credsPath = '/dbfs/Filestore/tables/credentials.json'
# Dans notre cas, nous utilisons une clé que nous avons téléchargée via Databricks file upload :
credsPath = '/dbfs/FileStore/tables/earth_engine_384112_03e2e02ee924.json'
# MOTEUR À TERRE UNIQUEMENT :
# Nous pouvons alors initialiser une session :
credentials = ee.ServiceAccountCredentials(service_account, credsPath)
ee.Initialize(credentials)
# Testons-le :
print(ee.Image("NASA/NASADEM_HGT/001").get("title").getInfo())
Utilisation d'une clé privée téléchargée sur le stockage DHSF
importation ee
import json
# Entrez l'email associé à votre compte de service créé à l'étape 3 :
compte_service = 'my-service-account@...gserviceaccount.com'
# Dans notre cas :
compte_service = 'david-rene@earth-engine-384112.iam.gserviceaccount.com'
# Entrez le chemin d'accès à vos informations d'identification :
credsPath = '/mnt/fsdh-dbk-main-mount/path/to/credentials.json'
# Dans notre cas, nous utilisons une clé que nous avons téléchargée dans le stockage DHSF :
credsPath = '/mnt/fsdh-dbk-main-mount/David/earth-engine-384112-72d27e31c3b7.json'
json_rows = spark.read.text(credsPath).collect() # Lire le fichier en utilisant spark
creds = json.loads("".join([row.value for row in json_rows])) # Chargement dans un fichier json/dict correct
# Dépose dans un fichier json avec le nom d'origine mais dans le dépôt de fichiers
newPath = "/dbfs/FileStore/tables/"+credsPath.split("/")[-1]
avec open(newPath, "w") as f :
json.dump(creds,f)
# MOTEUR À TERRE UNIQUEMENT :
# Nous pouvons alors initialiser une session :
credentials = ee.ServiceAccountCredentials(service_account, newPath)
ee.Initialize(credentials)
# Testons-le :
print(ee.Image("NASA/NASADEM_HGT/001").get("title").getInfo())