
Travailler avec Conda
Les Databricks peuvent prendre en charge des environnements basés sur Conda. DHSF offre deux options aux utilisateurs pour travailler avec Conda.
- Image Docker spécifique au projet avec le support Conda et un environnement Conda prédéfini. L'image Docker doit être co-développée avec l'équipe de support DHSF et poussée vers le GitHub Container Registry (GHCR).
- Image Docker générique avec support Conda. Les utilisateurs devront installer les paquets dans leurs ordinateurs portables.
À titre d'illustration, les étapes suivantes sont basées sur l'option 1.
Étape 1 : Créer l'environnement YAML
Exemple de code pour env.yml. Passez à l'étape 3 si vous utilisez une image Docker existante.
nom : fsdh-sample
canaux :
- bioconda
- par défaut
dépendances :
- python=3.8.16
- pip=23.0.1
- six=1.16.0
- ipython=8.12.0
- nomkl=3.0
- numpy=1.24.3
- pandas=1.1.5
- traitlets=5.7.1
- roue=0.38.4
- hifiasm=0.16.1
- pip :
- pyarrow==1.0.1
Étape 2. Construire et pousser l'image
L'équipe DHSF construit et pousse l'image sur GitHub. Passez à l'étape 3 si vous utilisez une image Docker existante.
docker build -t fsdh-sample .
export GHCR_PAT="XXX"
echo $GHCR_PAT|docker login ghcr.io -u <username> --password-stdin
docker tag fsdh-sample ghcr.io/ssc-sp/fsdh-sample:latest
docker push ghcr.io/ssc-sp/fsdh-sample:latest
Étape 3. Créer un cluster
- Demandez à votre administrateur d'activer Container Service pour votre espace de travail Databricks.
- Créez un cluster avec le mode d'accès "No Isolation Shared" (pas d'isolation partagée)
- Choisissez une durée d'exécution de 10.4-LTS, 9.1-LTS ou 7.3-LTS.
- Sous Advance -> Docker, utilisez l'image
ghcr.io/ssc-sp/fsdh-sample:latest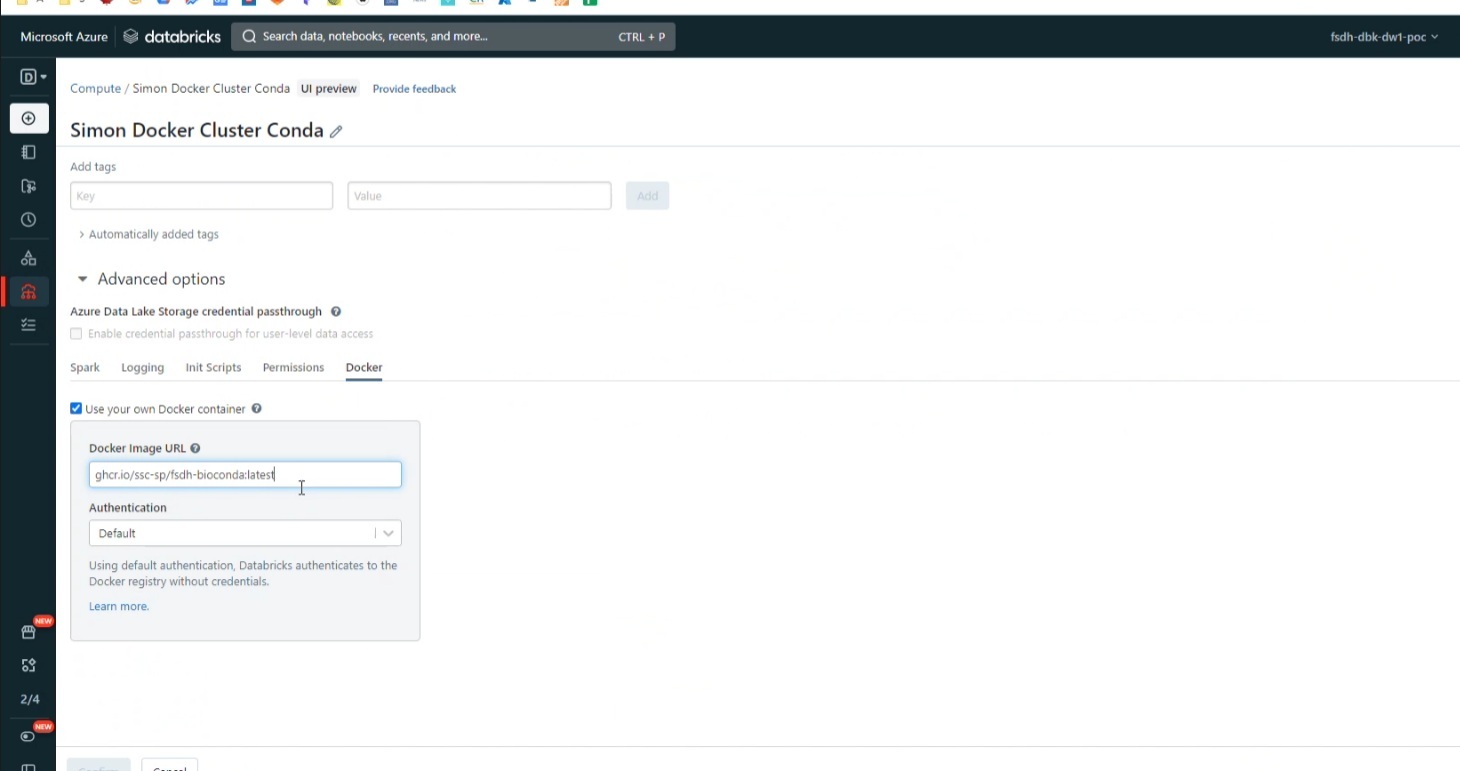
Étape 4. Valider le cluster
Exécutez le code suivant :
%sh
liste de conda