
Commencer avec Databricks sur le DataHub scientifique fédéral
Databricks est une plateforme unifiée d'analyse de données qui combine la puissance d'Apache Spark avec un environnement collaboratif pour la science des données et l'apprentissage automatique. Elle fournit un environnement cloud entièrement géré, évolutif et sécurisé pour le traitement des données, l'analyse et les charges de travail d'apprentissage automatique.
Ce guide vous aidera à démarrer avec Databricks sur le DataHub scientifique fédéral. Il se concentre sur :
- Provisionnement et accès aux Databricks à partir du DataHub
- Gestion des clusters Databricks
- Créer et gérer des carnets de notes
Approvisionnement et accès aux banques de données à partir du DataHub
Pour commencer à utiliser Databricks sur le DataHub scientifique fédéral, vous devez provisionner un espace de travail Databricks et y accéder depuis le portail DataHub.
Provisionnement d'un espace de travail Databricks
Note: Seul un administrateur d'espace de travail DataHub ou un responsable d'espace de travail peut approvisionner un espace de travail Databricks.
Pour approvisionner un espace de travail Databricks :
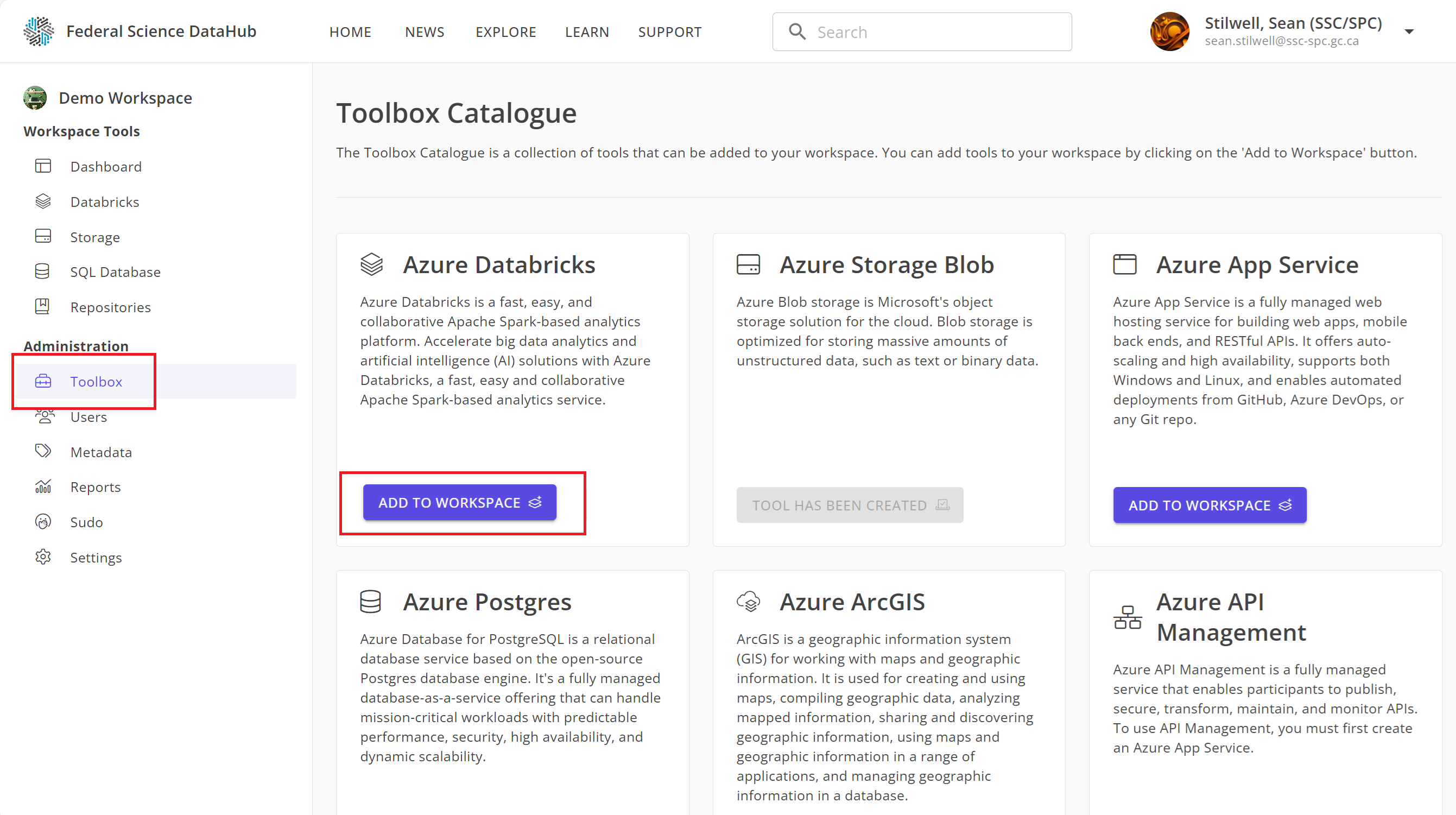
- Accédez à votre espace de travail DataHub.
- Cliquez sur l'onglet "Boîte à outils" sur le côté gauche.
- Sous la carte Databricks, cliquez sur
Add to Workspace.
Après quelques minutes, l'espace de travail Databricks sera provisionné et ajouté à votre espace de travail DataHub.
Accéder à Databricks à partir du DataHub
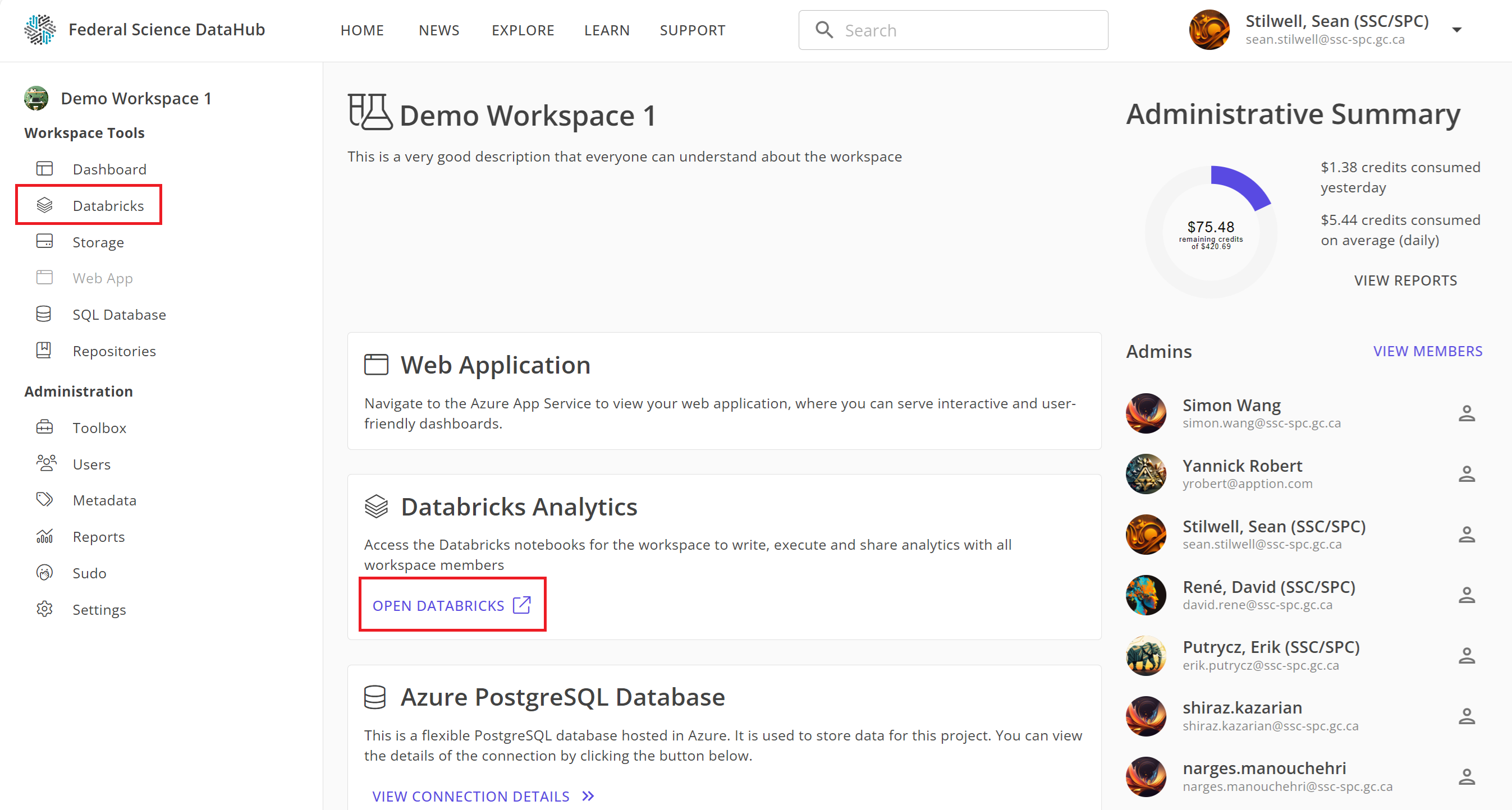
Une fois l'espace de travail Databricks provisionné, vous pouvez y accéder depuis le portail DataHub de deux manières :
- Cliquez sur
Databricksdans la barre latérale gauche, ou - Depuis le tableau de bord, cliquez sur
Open Databrickssous la carte Databricks.
Note: Il vous sera demandé de vous connecter à nouveau en utilisant vos identifiants M365 (les mêmes que ceux utilisés pour se connecter au portail DataHub).
Gestion des clusters Databricks
Les clusters Databricks sont des groupes de machines virtuelles qui alimentent vos charges de travail de traitement des données et d'analyse. Vous pouvez créer, gérer et mettre fin à des clusters à partir de l'espace de travail Databricks.
Par défaut, nous créons le main_cluster que nous vous recommandons d'utiliser pour vos charges de travail. Il est déjà configuré pour accéder à votre compte de stockage. Parfois, vous pouvez avoir besoin de créer différents clusters pour d'autres charges de travail.
Création d'un cluster Databricks
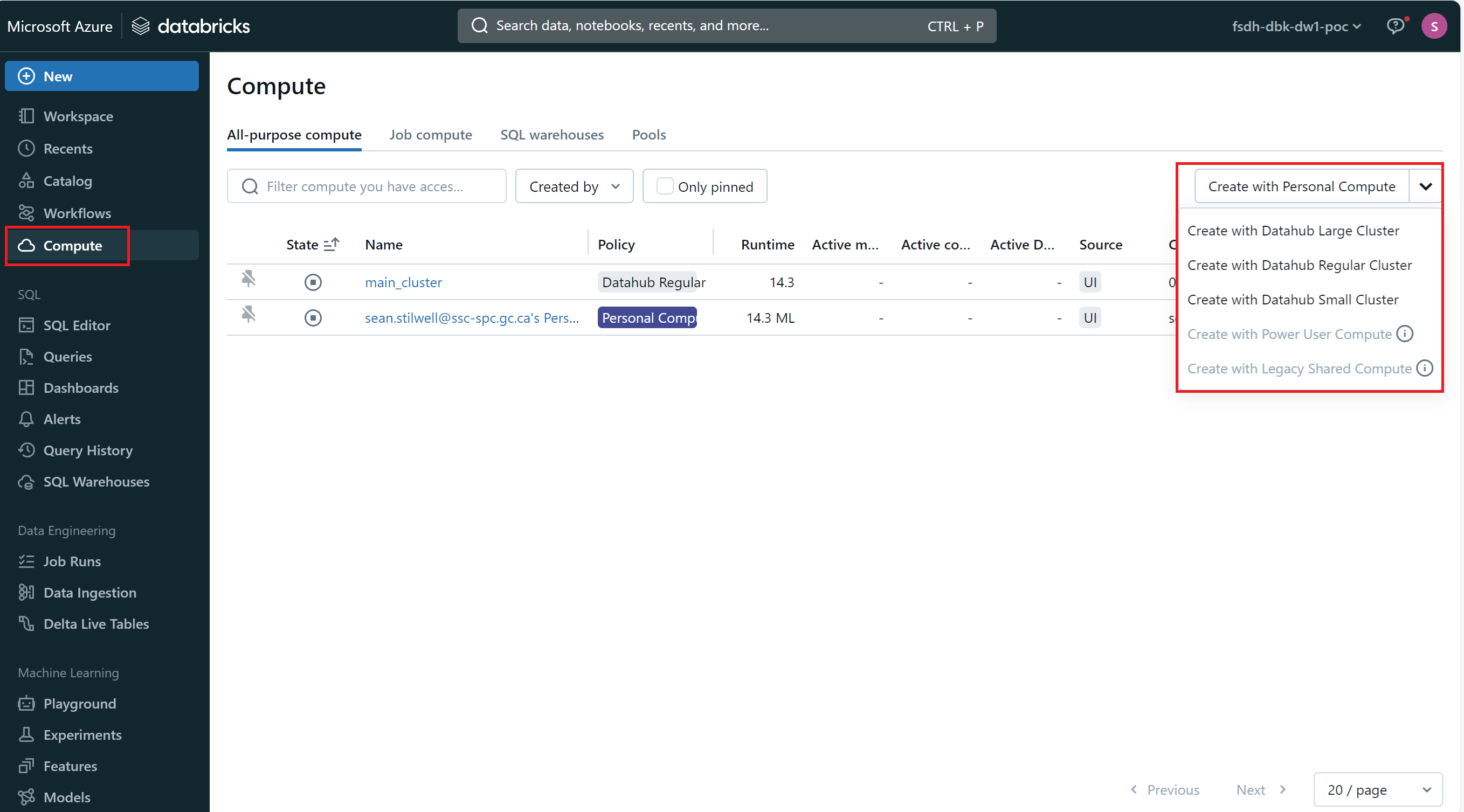
Pour créer un nouveau cluster Databricks :
- Naviguez vers l'espace de travail Databricks.
- Cliquez sur l'onglet
Computedans la barre latérale de gauche. - Cliquez sur
Create with Personal Computeou choisissez l'un des types de clusters préconfigurés dans la liste déroulante. - Configurez les paramètres du cluster, tels que le nom du cluster, le type d'instance et le nombre de nœuds de travail.
- Cliquez sur
Create Cluster.
Le nouveau cluster sera créé et prêt à être utilisé.
Note: Nous fournissons un guide détaillé sur les différents clusters. Vous pouvez vous référer au guide Politiques de clusters pour plus d'informations.
Démarrage et arrêt d'un cluster Databricks
Pour démarrer ou arrêter un cluster Databricks :
- Naviguez vers l'espace de travail Databricks.
- Cliquez sur l'onglet
Computedans la barre latérale de gauche. - Cliquez sur le cluster que vous souhaitez démarrer ou arrêter.
- Cliquez sur
StartouTerminatepour gérer le cluster.
Créer et gérer des carnets de notes
Les carnets de notes Databricks sont des documents interactifs qui contiennent du code, des visualisations et du texte narratif. Vous pouvez créer, modifier et exécuter des notebooks dans l'espace de travail Databricks.
Si vous connaissez les notebooks Jupyter, les notebooks Databricks sont similaires, mais avec des fonctionnalités et des intégrations supplémentaires.
Création d'un carnet de notes Databricks
Pour créer un nouveau carnet Databricks :
- Naviguez vers l'espace de travail Databricks.
- Cliquez sur l'onglet "Espace de travail" dans la barre latérale de gauche.
- Cliquez sur le dossier dans lequel vous souhaitez créer le carnet.
- Cliquez sur "Créer" et sélectionnez "Carnet de notes".
En haut du carnet, vous pouvez sélectionner le type de code que vous souhaitez écrire. Vous avez le choix entre Python, Scala, SQL et R.
Vous pouvez maintenant commencer à écrire du code, à ajouter des visualisations et à documenter votre travail dans le carnet. Vous devriez donner à votre carnet un nom significatif pour vous aider à identifier son objectif.
Écrire du code dans un carnet de notes Databricks
Les notebooks Databricks prennent en charge plusieurs langages de programmation, notamment Python, Scala, SQL et R. Vous pouvez écrire du code dans différentes cellules et les exécuter de manière interactive.
Les carnets sont divisés en différentes cellules. Vous pouvez exécuter chaque cellule individuellement ou exécuter l'ensemble du carnet. Cela vous permet de tester et d'itérer sur votre code facilement.
Vous pouvez également inclure des cellules de texte avec Markdown. Cela vous permet de documenter votre code, d'expliquer votre processus de réflexion et d'ajouter des visualisations à votre carnet.
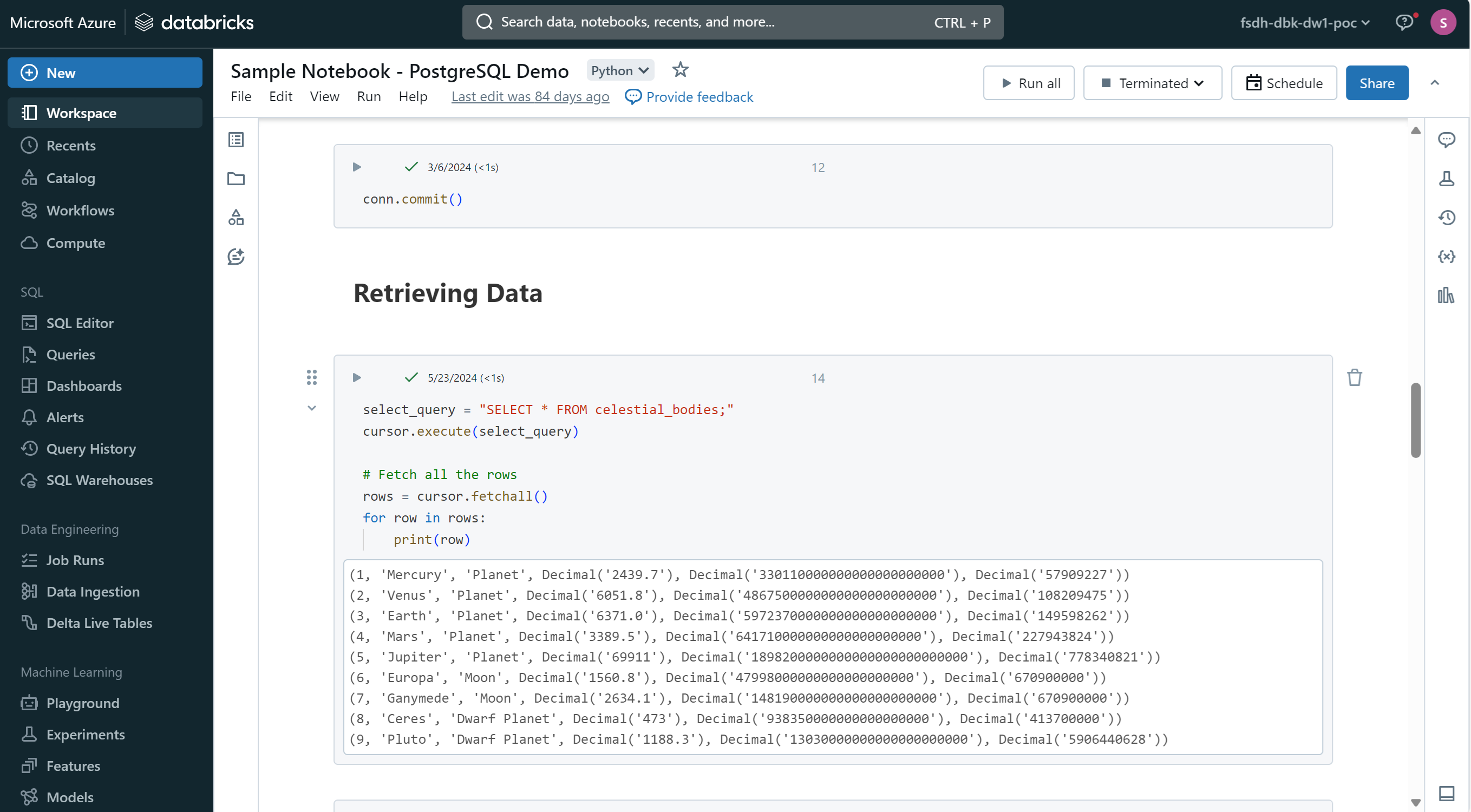
Accès à votre compte de stockage dans Databricks
Le cluster par défaut main_cluster est déjà configuré pour accéder à votre compte de stockage. Vous pouvez accéder à vos données stockées dans Azure Blob Storage, AWS S3, ou Google Cloud Storage directement depuis votre notebook Databricks.
Avec Python, utilisez le code suivant pour accéder à un fichier dans votre compte de stockage :
df = spark.read.option("header", "true").csv('/mnt/fsdh-dbk-main-mount/sample.csv') ;
Avec R, utilisez le code suivant pour accéder à un fichier dans votre compte de stockage :
library(SparkR)
sparkR.session()
df <- read.df("dbfs:/mnt/fsdh-dbk-main-mount/sample.csv", source = "csv")
Remplacez sample.csv par le chemin de votre fichier dans le compte de stockage.
Exécuter un Notebook Databricks
Pour exécuter un carnet Databricks :
- Écrivez votre code dans les cellules du carnet.
- Cliquez sur le bouton "Exécuter" en haut du bloc-notes pour exécuter le code dans la cellule actuelle.
- Vous pouvez également utiliser le raccourci clavier
Shift + Enterpour exécuter la cellule en cours et passer à la suivante.
Vous pouvez exécuter des cellules individuelles ou l'ensemble du cahier. L'exécution d'une cellule affiche la sortie sous la cellule.
Conclusion
Ce guide fournit une vue d'ensemble de la mise en route de Databricks sur le DataHub scientifique fédéral. Il couvre le provisionnement et l'accès à Databricks depuis le DataHub, la gestion des clusters Databricks, et la création et l'exécution de notebooks.
Databricks fournit un environnement puissant pour le traitement des données, l'analyse et l'apprentissage automatique. En exploitant Databricks sur le DataHub, vous pouvez collaborer avec votre équipe, analyser des données et construire des modèles d'apprentissage automatique dans un environnement sécurisé et évolutif basé sur le cloud.
Pour des sujets plus avancés et des guides approfondis, vous pouvez explorer notre section Learn ou vous référer à la documentation officielle de Databricks.